

Введение
Современные тенденции в бизнесе подразумевают переход от ручных расчетов к автоматизированным системам управления запасами, что позволяет сократить время и силы, затрачиваемые на механическое подсчетное число. Наибольшая часть рабочего времени менеджера отдела снабжения, затрачиваемая на механический подсчет необходимого объема пополнения запаса по каждой единице номенклатуры, обычно наблюдается в компаниях, которые не используют современные информационные технологии и автоматизированные системы учета и контроля запасов. Последние годы, согласно исследованиям, отмечается рост интереса к автоматизации, наряду с оптимизацией бизнес-процессов, как к наиболее приоритетным сферам управления [12, 3, 11]. Но крупные предприятия имеют ресурсы для использования данных для принятия решений и планирования. А малые и средние предприятия (МСП) обычно обладают ограниченными ресурсами и знаниями, что влияет на их способность собирать и использовать данные. Таким образом, перед ними стоит задача внедрить инструменты поддержки принятия решений, чтобы смягчить последствия рыночной неопределенности [4]. Барьеры внедрения технологий 4.0 на МСП исследователи делят на четыре группы: (1) технические, (2) организационные, (3) технологические и (4) правовые барьеры [1]. МСП должны инвестировать в первую очередь в области структур данных и их доступности, чтобы создать основу для анализа, основанного на данных [6].
Однако, даже если компании найдут ресурсы для автоматизации процессов планирования и прогнозирования, важна комплексность подхода. Исторически сложилось так, что две части одной и той же функции «прогнозирования запасов» рассматривались как отдельные части – управление запасами и прогнозирование спроса на запасы. Понимание каждой из этих двух частей безусловно важно, но необходимо взглянуть на «прогнозирования запасов» как на целое, то есть интегрированный контроль запасов и прогнозирование [5]. И компании действительно начали ставить в приоритет повышение зрелости процессов планирования потребности [12]. Так как исследования показывают (опрос 3 000 респондентов, проведенный SAP и Координационным советом по логистике (РФ)), что информационные системы управления/прогнозирования/планирования спроса используют лишь 16% участников [9].
Исследователи отмечают, что при построении прогноза продаж необходимо учитывать тип спроса – плавный, неустойчивый, неравномерный, перемежающийся. Прерывистые паттерны в продажах могут привести к росту ошибки прогноза и, как следствие, к избыточным запасам или низкому уровню обслуживания [7]. Создание избыточных запасов МСП с целью поддержанию необходимого уровня клиентского сервиса приводит к неоправданно большим операционным расходам [2]. Переход с ручной системы на информационную систему прогнозирования, которая будет делать это корректнее и быстрее, позволит выделить время на корректировку прогноза, а в розничной торговле любая автоматизация процессов ведет к улучшению уровня сервиса [8].
Целью данного исследования является разработка алгоритма, способствующему увеличению точности прогноза. Разработанный алгоритм можно интегрировать в информационную базу компании, и на основе прошлых данных по заданным алгоритмам будут производиться необходимые вычисления, ранее выполнявшиеся менеджерами. Такая автоматизация будет способствовать снижению рисков неопределенности спроса, способствовать определению оптимальных объемов закупки сырья у различных поставщиков (как от оптовых предприятий, так и от производителей), увеличивать эффективность закупочной деятельности.
Между заказом и доставкой товара существует временной интервал, требования клиентов не предопределены, и для преодоления этой неопределенности требуется оптимизация управления запасами.
Решением данного вопроса является автоматизация подсчета необходимой нормы закупки по каждому наименованию. Автоматизация подразумевает под собой написание программы, которая будет интегрирована в имеющуюся информационную базу, и на основе прошлых данных по заданным алгоритмам будет производить необходимые вычисления, ранее выполнявшиеся менеджерами, предоставляя лишь сводный готовый результат.
Материалы и методы исследования
Для анализа имеется сводная таблица продаж по каждому наименованию номенклатуры понедельно за 2019-2022 года. Для проверки качества используемых формул будет идти сравнение расчетных показателей на 2022 год, полученных на основе данных за 2019-2021 гг., и фактических за 2021 год.
Для построения модели прогнозирования спроса предлагается использовать методы анализа временных рядов и экспоненциального сглаживания. Эти методы предлагаются поскольку у нас есть исторические данные временных рядов, в которых есть долгосрочные тренды, сезонные колебания или циклы. Имеющиеся данные содержат достаточное количество наблюдений для выявления временных закономерностей и трендов.
Анализ временных рядов помогает понять структуру данных и выделить важные закономерности, а методы сглаживания помогают улучшить прогнозы и устранить шумы во временном ряду. Они часто взаимосвязаны и могут использоваться вместе в процессе прогнозирования продаж.
Ограничения исследования
Сложность задачи построения алгоритма действий заключается в том, что существует множество факторов, оказывающих влияние на принятие решения о пополнении запасов. Все их учесть очень трудно, поэтому сразу сделаем перечень условий, в рамках которых будем строить нашу модель:
1) Весь товар хранится на одном складе. Его объем будем считать неограниченным.
2) Все поставки ведутся от российских поставщиков, поэтому поставка возможна в течение недели.
3) Итоговые расчеты должны стремиться к оптимальным значениям соотношения «текущий запас/продажи». Максимальной эффективности добиться не удастся вследствие невозможности учета на данном этапе ряда факторов (например, транспортный, удаленность и мощности поставщиков, сопутствующие риски и т.д.).
4) Алгоритм не учитывает упущенную выгоду (потенциально непроданный товар).
Построение модели
Сам алгоритм строится на основе прогноза продаж. Стоит отметить, что точно спрогнозировать продажи на каждую неделю при подобной форме и специализации магазина почти невозможно, поэтому одной из главных подзадач становится минимизация влияния выбросов из статистических данных.
Для оценки будущих продаж выделим две основные составляющие – это тренд и сезонность. Тренд используется для прогноза на основе данных за последние несколько недель, которые учитывают текущую тенденцию и настрой потребителей. Сезонность показывает, насколько потребители активны в те или иные периоды времени. Важно отметить, что специфика товаров магазина такова, что сезонность выпадает либо на летний (теплый) период, либо на зимний (холодный). Таким образом, мы подразумеваем, что она может встречаться единым неразрывным периодом не более 1 раза в год.
Первым шагом будет построение массива. Строка массива – отдельный товар. Каждой ячейке соответствует определенное числовое значение – объем продаж данного товара за конкретный период. Каждая ячейка соответствует определенной неделе (записываются последовательно). Для каждого товара строка массива будет начинаться с первой непустой ячейки (первый период с продажами), порядковый номер ячейки данной недели будет 1. Порядковый номер ячейки недели, на которую будем осуществлять прогноз, будет n.
Следующим действием будет определение доступного периода данных. В частности, нас интересует, сколько периодов с разницей в год мы имеем. Это необходимо для определения сезонности.
Таким образом:
t = округление в меньшую сторону выражения
((n – 2) / 52), (1)
где t – число сезонных периодов для расчета.
«n-2» мы используем именно потому, что в дальнейшем нам придется рассматривать период и с интервалом в год в составе месяца, то есть ± 2 недели. Именно 2 недели предшествующие интервальной разнице необходимо учесть.
Далее возможны 3 варианта:
1) t = 0. Это означает, что товар относительно новый, и мы не можем пока судить о его сезонности. Если данного товара еще вообще не было в продаже, то запас на первые 6 недель просчитывает менеджер вручную.
2) t = 1. Есть данные только о прошлогоднем периоде, которые стоит принимать во внимание, но о тенденции судить пока нельзя.
3) t ≥ 2. Можно сделать выводы о том, является ли товар сезонным.
Далее нам надо установить, насколько сильное влияние может оказывать фактор сезонности на потребление товара для t ≥ 1. Для этого мы выделим предполагаемый сезонный период (неделю) Xn, найдем в массиве данных данные по продажам за неделю равно за год до прогнозируемой недели (то есть ровно 52 недели назад до прогнозируемой недели). Затем условно сравним объем продаж за период – найденная прошлогодняя неделя с дополнительным охватом ± месяц (то есть 4 недели до нее и 4 после) – с объемом продаж за полугодовой интервал (6 месяцев х 4 недели = 24 недели), следующий через 2 месяца после охваченного периода. 6 месяцев – максимальный интервал, который практически исключает вероятность перекрытия со следующим сезонным периодом. Если данное соотношение будет не менее, чем в 2 раза, значит влияние сезона очень сильное. В формульном виде это соотношение будет записано следующим образом:
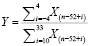 , (2)
, (2)
где Y – уровень влияния сезона, Xn – числовое значение ячейки массива с порядковым номером n, i – неделя.
Если Y ≥ 2, то такое влияние будем считать существенным, что отразится у нас в дальнейшем на выборе метода расчета.
Стоит отметить, что формула (2) применима только для случая t = 1, причем однозначного вывода о наличии сильного сезонного фактора сделать нельзя. В этом случае менеджеру должно даваться уведомление о наличии данной ситуации, где он уже сможет самостоятельно принять решение о том, имеет ли место здесь сильное влияние сезонности.
Если t ≥ 2, то помимо формулы (2) проверка будет осуществляться также и по следующей формуле:
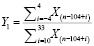 , (3)
, (3)
где Y1 – уровень влияния сезона с интервалом от прогнозируемого периода в 2 года (104 недели), Xn – числовое значение ячейки массива с порядковым номером n, i – неделя.
Таким образом, мы будем констатировать наличие сильного сезонного фактора только в случае, если Y ≥ 2 и Y1 ≥ 2.
Теперь приступим к построению самого прогноза продаж. Для этого вернемся к понятиям тренда и сезонности. В общем виде прогноз продаж будет определяться следующим образом:
Xn = (k1 × фактор сезонности +
+ k2 × фактор тренда) × M + P, (4)
где k1 и k2 – весовые доли факторов, их сумма равна 1;
M – универсальный маркетинговый коэффициент. Он нужен для корректировки расчетного значения с учетом влияния различных мероприятий, проводимых отделом маркетинга или иных указаний руководства, а также влияния внешних факторов, например политического. В себя он может включать несколько различных коэффициентов-множителей, но итоговым результатом будет общее число. По умолчанию равен 1;
P – возможность ручной регулировки объема заказа путем добавления/вычитания нужного числа единиц товара. Чаще всего будет использоваться в случаях случайной порчи/утери запасов или возврата от покупателей. Стандартно берется за 0.
Для коэффициентов k1 и k2 установим значения соответственно:
1) при t=0: k1=0, k2=1. Данных по сезонности у нас нет, учитываем только влияние тренда;
2) при t ≥ 1, Y < 2 или Y1 < 2: k1=0,4, k2=0,6 (несезонный товар);
3) при t ≥ 2, Y ≥ 2 и Y1 ≥ 2: k1=0,8, k2=0,2 (сезонный товар);
4) при t = 1, Y ≥ 2 и Y1 ≥ 2: коэффициенты будут аналогичными второму или третьему случаю, в зависимости от решения менеджера.
Значения данных коэффициентов определяются методом перебора и приблизительной оценки лучших результатов. Для более точной оценки необходимо проводить полномасштабное изучение рынка для выявления уровня влияния данных факторов.
Теперь более детально рассмотрим тренд. Для него мы будем использовать период в 6 недель, предшествующий неделе заказа. Так как в наших условностях период поставки составляет 1 неделю, поэтому мы будем использовать данные по продажам со 2 по 7 неделю до заказа:
Фактор тренда = 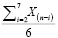 . (5)
. (5)
Аналогично с помощью среднего арифметического можно дать общее представление о факторе сезонности, однако для него мы будем рассматривать период в 5 недель (1 неделя с интервалом в год от прогнозируемой ± 2 недели):
Фактор сезонности = 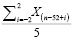 . (6)
. (6)
где Xn – числовое значение ячейки массива с порядковым номером n, i – неделя.
В случае t ≤ 1 формул (5) и (6) почти достаточно для построения прогнозирования, однако для повышения точности необходимо учесть статистические выбросы. В нашем случае выбросы – это значения, максимально отклоняющиеся от среднего по модулю и вносящие наибольшее влияние в средний показатель. Это может быть связано, например, с большим заказом нового клиента или выигрыша тендера на поставку. Такие значения носят единовременный характер и негативно сказываются на построение прогноза.
Так как из каждого фактора мы используем относительно небольшое число значений, то для каждой группы будем убирать только одно наиболее значительное. Для этого придется завести новый массив, куда будут записываться ссылки на исследуемые ячейки с их значениями. Затем эти значения ранжируются в порядке возрастания. После чего необходимо сравнить абсолютное отклонение первого (минимального) и последнего (максимального) значений от среднего арифметического всей группы. Ячейка с максимальным абсолютным отклонением будет считаться выбросом и учитываться при подсчете фактора не будет.
Фактор тренда = 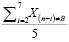 , (7)
, (7)
где Xn – числовое значение ячейки массива с порядковым номером n, Xв это значение ячейки с максимальным абсолютным отклонением, в – порядок ячейки выброса, i – неделя.
После полной отработки цикла массив с данными очищается. В итоге наши прежние формулы (6) и (7) примут несколько другой вид:
Фактор сезонности =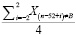 , (8)
, (8)
где Xв это значение ячейки с максимальным абсолютным отклонением, в – порядок ячейки выброса, i – неделя.
Тем не менее, помимо статистических выбросов может быть довольно большой величина среднеквадратического отклонения (СКО) значений за период. Это означает, что колебания спроса достаточно велики в коротком промежутке времени, поэтому их тоже придется учитывать. В общем виде для нашего массива данных формула СКО имеет вид:
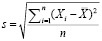 , (9)
, (9)
где Xi – объем продаж за неделю i, 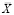 – среднее арифметическое за исследуемый период, n – количество недель.
– среднее арифметическое за исследуемый период, n – количество недель.
В нашем случае для тренда СКО можно переписать как:
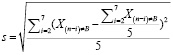 , (10)
, (10)
где Xn – числовое значение ячейки массива с порядковым номером n, Xв это значение ячейки с максимальным абсолютным отклонением, в – порядок ячейки выброса, i – неделя.
Тогда конечная формула учета влияния тренда будет:
Фактор тренда = 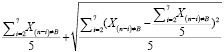 , (11)
, (11)
где Xn – числовое значение ячейки массива с порядковым номером n, Xв это значение ячейки с максимальным абсолютным отклонением, в – порядок ячейки выброса, i – неделя.
СКО будет как раз играть роль при формировании страхового запаса, необходимого для увеличения вероятности перекрытия пика флуктуаций спроса.
Формула учета сезонности будет иметь аналогичные изменения:
Фактор сезонности = 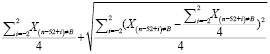 , (12)
, (12)
Однако при рассмотрении сезонности нам приходится использовать более 1 периода. Разумеется, чем больше интервал между рассматриваемым периодом и прогнозируемым, тем меньшее влияние он будет оказывать оценке. Учитывая сильный фактор прогресса, изменчивости человеческих предпочтений и нестабильную экономическую обстановку в России, предположим, что скорее всего зависимость эта убывает экспоненциально. Для отслеживания изменения продаж путем проверки результатов и выходных данных с учетом различных факторов и присвоения им весов можно воспользоваться формулой экспоненциально взвешенного скользящего среднего (EWMA). Формула EWMA показывает значение скользящего среднего в момент времени n:
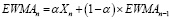 , (13)
, (13)
где α (альфа) – коэффициент сглаживания, определяющий вес текущего значения в среднем. Обычно α выбирается в интервале от 0 до 1, чем ближе к 1, тем больше вес отдается текущему значению;
Xn – значение серии в текущем периоде n.
EWMAn–1 – значение EWMA на предыдущем периоде.
Таким образом, формула EWMA представляет собой рекуррентное уравнение, которое позволяет вычислять среднее значение последовательности данных с учетом весового коэффициента α.
Сглаживающая константа α в формуле экспоненциально взвешенной скользящей средней (EWMA) используется для определения веса каждого значения в ряде данных. Чем больше значение α, тем больше вес у последних наблюдений, и наоборот. Для вычисления сглаживающей константы можно использовать следующую формулу:
α = 2 / (t+1), (14)
где α – сглаживающая константа, t – количество периодов (наблюдений) в ряде данных.
Именно α и будет определять все наши коэффициенты.
Представим сначала расчет сглаживающей константы α в табличном виде. Это поможет вывести формулу, которая может использоваться для определения весов элементов последовательности. Введем обозначение коэффициента zi, где i будет изменяться в пределах от 1 до t. Для наглядности построим таблицу коэффициентов α, при t от 1 до 5.
Из таблицы хорошо прослеживается закономерность построения коэффициентов.
Таким образом, в формульном виде определение итогового взвешенного среднего значения zi можно записать так:
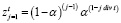 , (15)
, (15)
где z – обозначает итоговое взвешенное среднее значение.
j, t – это переменные, где j принимает значения от 1 до t включительно, а t – это общее количество значений в ряде данных.
α – это коэффициент сглаживания, который определяет вес текущего значения в среднем. Чем больше значение α, тем больший вес имеет текущее значение.
div – функция возврата целого числа от целочисленного деления.
Таблица 1
Расчет сглаживающей константы α
|
zi t |
1 |
2 |
3 |
4 |
5 |
|
2 |
α |
(1 – α) |
|||
|
3 |
α |
(1 – α)α |
(1 – α)2 |
||
|
4 |
α |
(1 – α)α |
(1 – α)2 α |
(1 – α)3 |
|
|
5 |
α |
(1 – α)α |
(1 – α)2 α |
(1 – α)3 |
(1 – α)4 |
В формуле эта взвешенная сумма представляется как произведение двух частей:
- первая часть (1 – α)(j–1) – это весовой множитель для предыдущих значений.
- вторая часть α(1–j div t) – это весовой множитель для текущего значения.
В конечном итоге формула для вычисления весового коэффициента при определении сезонной компоненты модели прогнозирования спроса (фактора сезонности) будет переписана в следующем виде для t ≥2:
Фактор сезонности =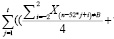
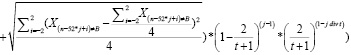 (16)
(16)
где Xn – числовое значение ячейки массива с порядковым номером n, Xв это значение ячейки с максимальным абсолютным отклонением, в – порядок ячейки выброса, i – неделя, j – год, t – число сезонных периодов для расчета
Подставив все значения в общую формулу (4), получим прогнозное значение продаж на неделю n:
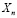 =(
=(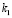 *
*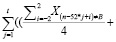
+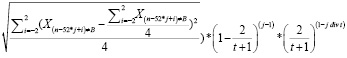 ) +
) +
+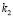 *<
*<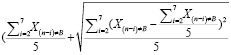 )*M+P, (17)
)*M+P, (17)
Почти все прогнозные значения будут представлять собой нецелое число. Для удобства сделаем округление Xn в большую сторону. Для того, чтобы оценить эффективность предложенной формулы, сравним расчетные показатели на 2022 год с фактическими (Xф). Всего возможно 3 варианта исхода по каждому значению:
1) Xn ≈ Xф. Расхождение в среднем составляет не более 15%, считаем прогноз довольно точным. Стоит отметить, что в основном получается небольшое превышение, что однозначно лучше, так как в этих случаях нет упущенной прибыли.
2) Xn  Xф. Данная ситуация может возникнуть с новыми товарами, по которым еще нет достаточно статистики или пришлось сильное воздействие внешних факторов. Число таких прогнозов крайне мало, так как применение СКО в формулах очень хорошо выполняет роль просчета резервов.
Xф. Данная ситуация может возникнуть с новыми товарами, по которым еще нет достаточно статистики или пришлось сильное воздействие внешних факторов. Число таких прогнозов крайне мало, так как применение СКО в формулах очень хорошо выполняет роль просчета резервов.
3) Xn  Xф. Довольно распространенная ситуация, особенно вытекающая из неучтенного фактора сильного падения реальных доходов потребителей за последнее время. В некоторых случаях превышение достигает несколько сотен процентов, однако такая ситуация происходит только с товарами, которые раньше находились в ценовой категории «средняя+» и были относительно популярны, а сейчас предпочтение отдается более дешевым аналогам, и в данном случае Xф ≤ 2.
Xф. Довольно распространенная ситуация, особенно вытекающая из неучтенного фактора сильного падения реальных доходов потребителей за последнее время. В некоторых случаях превышение достигает несколько сотен процентов, однако такая ситуация происходит только с товарами, которые раньше находились в ценовой категории «средняя+» и были относительно популярны, а сейчас предпочтение отдается более дешевым аналогам, и в данном случае Xф ≤ 2.
Тем не менее 3-й случай перестает быть проблемой, когда рассматривается не с точки зрения прогноза продаж, а с точки зрения запасов. При самом плохом раскладе на небольшой промежуток времени образуется сверхнормативный запас, равный разнице Xn – Xф. Он будет составлять всего лишь несколько единиц товара. Через несколько недель влияние сезонного фактора ослабнет по сравнению с трендом, и прогнозирование выровняется. Также возможно избежать такой ситуации грамотным просчетом совокупного маркетингового коэффициента.
Размер заказа по товару будет равняться:
q = Xn – Зтек, (18)
где Зтек – уровень текущего запаса в натуральных единицах.
Вдобавок будет рациональным использование факта, что о части оптовых продаж мы знаем заранее по предварительным заказам. Таким образом, можно немного подстраховаться от упущенной выгоды. Для этого Xn мы умножаем на среднюю долю оптовых продаж компании (0,78) и вычитаем из числа гарантированных заказов qзак. Если qзак – 0,78Xn > 0, тогда разницу qзак – 0,78Xn с округлением в большую сторону мы прибавляем в регулируемый параметр P.
В конечном итоге раскроем формулу (18) для всех вариантов значений t:
1) t < 1: начинаем проверку условия “n/6≥1?”
a. n/6 < 1: расчет не производится, менеджер вручную контролирует запас, так как недостаточно данных;
b. n/6 ≥ 1:
q = 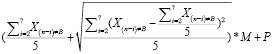 – Зтек, (19)
– Зтек, (19)
2) t = 1:
q = 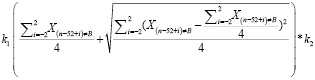 *
*
*(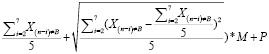 – Зтек, (20)
– Зтек, (20)
3) t≥2:
q=(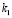 *
*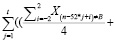
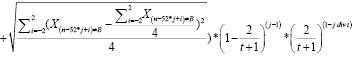 ) +
) +
+ 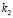 *
*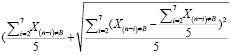 )*M+P– Зтек, (21)
)*M+P– Зтек, (21)
Величину заказа q будем округлять в большую сторону.
Коэффициенты k1 и k2 для 2-го и 3-го случая будут подставляться в зависимости от предварительных расчетов Y и Y1 по формулам (2) и (3) соответственно.
Результаты исследования и их обсуждение
Теперь сравним наши результаты с фактической работой менеджера за 2022 год. Оценка будет проводиться с помощью сравнения реально доступного товара на период и фактического объема продаж. В случае с алгоритмом количество имеющегося товара на складе будет равно прогнозу продаж, соответствующему формуле (17). В случае с менеджером объем доступного товара на неделю n составит:
Qn = Qост n–1 +qn, (22)
где Qn – величина запаса на неделю n,
Qост n–1 – величина остатка запаса на конец предыдущей недели,
qn – количество поступившего товара в неделю n.
Затем нам потребуется 2 массива данных со значением в каждой n-й ячейке:
1) Xn – Xф: разница между прогнозом и фактом в натуральных единицах.
2) Xn / Xф: отношение объема прогноза продаж к фактическому. Для получения более достоверных данных для любого Xn ≠ 0 все значения Xф = 0 заменим на 1. Это необходимо минимизации больших потерь данных из-за невозможности делить на 0.
Аналогичные операции выполним и для случая расчета менеджером, подставляя вместо Xn значение Qn из формулы (22).
Для полученных массивов считаем среднее арифметическое значение и среднеквадратическое отклонение. Первый показатель нам дает приблизительную оценку совокупного прогноза на длительный период, в то время как второй отвечает за точность прогноза на неделю.
В итоге получаем следующие значения:
1) Для алгоритма:
a.  = 5,14 – среднее арифметическое попарной разности данных показателей за искомый период;
= 5,14 – среднее арифметическое попарной разности данных показателей за искомый период;
b. CKOα1 = 3,61 – среднеквадратическое отклонение для массива попарных разностей;
c. 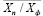 = 1,16 – среднее арифметическое попарных отношений Xn к Xф за искомый период;
= 1,16 – среднее арифметическое попарных отношений Xn к Xф за искомый период;
d. CKOα2 = 1,72 – среднеквадратическое отклонение для массива попарных отношений;
2) Для менеджера:
a.  = 5,4 – среднее арифметическое попарной разности Qn и Xф за искомый период;
= 5,4 – среднее арифметическое попарной разности Qn и Xф за искомый период;
b. CKOм1 = 11,2 – среднеквадратическое отклонение для массива попарных разностей;
c. 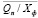 =1,58 – среднее арифметическое попарных отношений Qn к Xф за искомый период;
=1,58 – среднее арифметическое попарных отношений Qn к Xф за искомый период;
d. CKOм2 = 3,31 – среднеквадратическое отклонение для массива попарных отношений;
Как мы видим, у алгоритма все показатели немного ниже, чем у ручного расчета менеджера, что при условии критерия эффективности соответствие уровня запаса на неделю с его уровнем продаж, будет лучше. Все значения при расчете менеджером получились выше, так как он не ставит себе целью закупки объема на неделю, и как правило покупает на более долгий период, что увеличивает случаи возникновения сверхнормативного запаса. Однако это не означает, что это неэффективно с экономической стороны, так как может быть экономия за счет эффекта масштаба.
Если рассмотреть показатели, полученные при действии алгоритма, то можно ошибочно заключить, что величина CKOα2 =1,72 довольно большая, и закупок на неделю совершается намного больше. Однако если рассматривать более детально, то становится ясно, что большой вклад в это значение вносит группа товаров, которая ранее продавалась в гораздо большем количестве, чем сейчас из-за влияния внешних факторов. Так что вполне вероятно, что это показатель снижается правильным просчетом маркетологами предстоящих тенденций.
Данный алгоритм может быть интегрирован в базу 1С. 1С являлась наиболее распространенной системой уже несколько лет назад [12], а в силу текущих экономических и геополитических условий с уходом SAP, Oracle, Manhattan, тем более укрепила свои позиции (наряду с Axelot, Lead и др.) [10].
Заключение
Представленная исследование о модели прогнозирования спроса для оптимизации запасов на малом предприятии имеет целью разработку алгоритма, способствующего увеличению точности прогноза. Результаты исследования показали, что разработанный алгоритм, основанный на методах анализа временных рядов и экспоненциального сглаживания и учете факторов сезонности и тренда, способен получить прогнозное значение продаж на неделю n.
Для оценки эффективности предложенной формулы было проведено сравнение расчетных показателей на 2022 год с фактическими данными. Данный алгоритм теоретически справляется с поставленными задачами на уровне ручной работы менеджера и лучше. Полученные результаты показали, что формула демонстрирует немного более низкие значения, чем ручной расчет менеджера. Однако, при соблюдении критерия эффективности, который предполагает соответствие уровня запаса на неделю с его уровнем продаж, применение алгоритма приводит к лучшим результатам.
Алгоритм обеспечивает повышенную точность прогнозов. Но описанный алгоритм показывает хорошие результаты в заданном наборе ограничений. Описанная система не является наилучшей, так как не идет в расчет множество факторов, однако ее можно доработать, не изменяя ключевых принципов ее функционирования, таким образом она может быть адаптирована и для другого малого предприятия.
Кроме того, данный алгоритм может быть успешно интегрирован в информационную базу компании, что позволит автоматизировать процесс вычислений и снизить зависимость от человеческого фактора. Возможность интеграции алгоритма в базу 1С дает дополнительные преимущества для предприятия, позволяя сократить затраты на управление запасами и повысить эффективность предприятия в целом.
Библиографическая ссылка
Ценина Е.В., Слепенкова Е.В. МОДЕЛЬ ПРОГНОЗИРОВАНИЯ СПРОСА ДЛЯ ОПТИМИЗАЦИИ ЗАПАСОВ: ПРИМЕР МАЛОГО ПРЕДПРИЯТИЯ // Вестник Алтайской академии экономики и права. – 2023. – № 12-2. – С. 355-364;URL: https://vaael.ru/ru/article/view?id=3180 (дата обращения: 18.05.2024).