

Введение
В ходе работы в Департаменте бизнес-анализа Корпоративного центра ПАО «Ростелеком» со стороны высшего руководства были выдвинуты требования по подготовке периодических аналитических отчетов, связанных с оценкой результатов работы сотрудников департаментов по работе с корпоративным и государственным сегментами с доходными закупками в целях выполнения которых появилась необходимость в разработке модели машинного обучения, служащей основой для классификации текстовых наименований доходных закупок.
Цель исследования
Целью исследования является разработка и оценка моделей машинного обучения, основанных на анализе семантики естественного языка для классификации наименований доходных закупок в целях подготовки аналитической отчетности и ее оперативного предоставления высшему руководству для принятия управленческих решений.
Материал и методы исследования
В ходе исследования использовались данные наименований закупок с официального сайта единой информационной системы в сфере закупок. В процессе исследования применялись методы машинного обучения, такие как логистическая регрессия, градиентный бустинг, ближайшие соседи.
Результаты исследования и их обсуждение
Бизнес-задача состоит в анализе доходных закупок, а именно в выявлении среди них профильных закупок, чьи наименования принадлежат тематике «Связь» – предоставление доступа в интернет, оказание услуг мобильной связи, предоставление цифровых каналов связи и т.д. На основе выявленных профильных закупок руководство получает информацию о том, каким заказчикам не удалось оказать услуги связи по причине отсутствия сетевых ресурсов, о потенциальных потерях среди профильных закупок, а также о том, стоит ли и далее принимать участие в тех или иных закупках. Существуют большие временные затраты на формирование отчетов, что объясняется объемами закупок, поступающих для анализа. Проведен расчет затрат для проведения ручной классификации закупок (табл. 1).
Следует отметить, что при подготовке отчетов об участии в закупках более 80 % времени затрачивается только на проведение классификации закупок, что создает проблемные ситуации, связанные с оперативным предоставлением отчета руководству. В целях сокращения временных затрат на 70 % и уменьшения трудозатрат в 15 раз было положено начало разработке модели машинного обучения для классификации наименований закупок, в том числе на основе анализа семантики естественного языка. Языком программирования выбран высокоуровневый язык программирования Python, а средой разработки – служба Microsoft Azure Notebooks. Далее будет рассмотрен процесс построения модели машинного обучения согласно методологии Knowledge Discovery in Databases (KDD) и будет включать следующие этапы [1, с. 4-5]:
1. Сбор данных – извлечение исходных данных в виде текстового корпуса;
2. Предобработка данных – применение методов очистки данных;
3. Data Mining – выбор метода машинного обучения и построение модели для извлечения знаний из данных;
4. Оценка – измерение эффективности модели машинного обучения.
Постановку задачи в формальных терминах машинного обучения можно выразить следующим образом [2, с. 13]: Задано множество документов D = {d1,…,d|D|} и множество классов C = {c1,…,c|C|}. Неизвестная целевая функция Ф: D·C → {0, 1} задается формулой 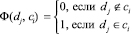 . Необходимо построить классификатор Ф': D·C → {0, 1}, максимально близкий к функции Ф. Другими словами, необходимо произвести бинарную классификацию текстовой информации с помощью способа машинного обучения с учителем.
. Необходимо построить классификатор Ф': D·C → {0, 1}, максимально близкий к функции Ф. Другими словами, необходимо произвести бинарную классификацию текстовой информации с помощью способа машинного обучения с учителем.
Таблица 1
Стоимость выполнения операций по подготовке аналитических отчетов
|
Операция ручной классификации закупок |
Частота выполнения, раз/мес. |
Трудоемкость, минут |
Денежные затраты, руб (ставка 1 000 руб./час) |
|
Отчет об участии в закупках по профилю «Мобильная связь» |
1 |
1 440 |
24 000 |
|
Отчет о выигранных закупках по профилю «Связь» |
4 |
440 |
29 333 |
|
Отчет о закупках по профилю «Связь» с отказами от участия |
1 |
1 500 |
25 000 |
|
Итого |
4 700 |
78 333 |
В данном случае необходима обработка текстовых данных на естественном языке, реализующаяся с помощью технологии Natural Language Processing (NLP), характеризующаяся использованием последовательных операций по обработке исходного текста для его дальнейшего преобразования в целях извлечения полезной информации [3, с. 53]. Для решения задач NLP требуется наличие подготовленных текстовых коллекций, называемых текстовыми корпусами. В целях выполнения первого этапа методологии KDD извлечена выборка наименований закупок объемом 16 809 закупок, а также проведена ручная разметка наименований на два класса: закупка профильная и закупка не профильная. На этапе предобработки данных необходимо произвести очистку текстового корпуса на основе приведения слов к нижнему регистру, токенизации по словам для разделения предложения наименования закупки на слова-компоненты, удаления стоп-слов для избежания шума в данных, а также проведения лемматизации слов, который заключается в приведении слова к лемме, к его канонической форме. Для совершения данного процесса необходимо воспользоваться морфологическими анализаторами, среди которых присутствует pymorphy2, способный для входящего слова в ходе совершения морфологического разбора произвести в том числе его нормализацию [4, с. 1]. В ходе выполнения второго этапа методологии KDD произведена предобработка исходного текстового корпуса (рис. 1).
Необходимо разбить предобработанный текстовый корпус на обучающую и тестовую выборки. В данном случае произведено разделение на две выборки в соотношении 7:3. Далее следует решить, каким способом будет происходить кодирование нормализованных наборов слов, так как модели машинного обучения способны работать с числовыми представлениями. Существует два основных способа для преобразования слов в векторы – прямое кодирование и векторное представление. Прямое кодирование основывается на понятии «мешок слов», который заключается в проведении векторизации элементов текстового корпуса (т.н. документов текстового корпуса), в результате которой размерность векторов определяется через мощность словарного запаса текстового корпуса, а элементы векторов равны количеству вхождений того или иного слова из словаря для элемента текстового корпуса. Составлен уникальный словарь для обучающей выборки мощностью 7 739 слов. Для уменьшения размерности мешка слов осуществлено исключение слов из уникального словаря, имеющих частотность десять слов и менее. Рассмотрение облака слов для низкочастотных слов, сформированного с помощью библиотеки WordCloud, реализованной на Python, дает основание для понимания факта их низкой ценности с точки зрения наличия в словаре (рис. 2).
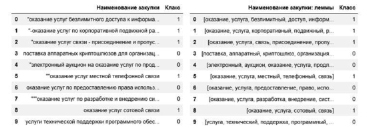
Рис. 1. Фрагмент размеченного текстового корпуса до и после предобработки

Рис. 2. Облака высокочастотных и низкочастотных слов
В результате оптимизации словаря его мощность составляет 1 105 слова, что положительно скажется на размерности мешка слов и эффективности работы модели в дальнейшем, и представляет из себя ценные слова для модели. На основе оптимизированного словаря сформирован мешок слов для обучающей выборки текстового корпуса. Количество измерений мешка слов определяется через мощность оптимизированного словаря, а количество строк определяется через количество документов обучающей выборки текстового корпуса. Сформированный мешок слов имеет размерность мощности словаря. Вторым способом преобразования слов является векторное представление. В случае использования векторного представления слов необходимо применять специальные дистрибутивно-семантические модели для появления возможности формирования набора плотных векторов. В основе одной из таких моделей, Word2Vec, содержится гипотеза о необходимости анализа ближайших контекстных слов, количество которых определяется задаваемым параметром скользящего окна, предназначенного для выявления закономерностей в рамках контекстного окружения слова [5, с. 82]. На основе заданного скользящего окна происходит продвижение по всему текстовому корпусу и вычисляется попарная встречаемость целевого слова с окружающими его словами. В результате совершенного продвижения формируются значения частоты встречи слов во всем текстовом корпусе, а также значение количества раз, которое слово скользящего окна находилось в контекстном окружении целевого слова. Далее происходит вычисление весов слов контекстного окружения по отношению к целевому слову. В данном случае векторы будут построены таким образом, что близкие по контексту слова, будут находиться на наиболее близком расстоянии. Расстоянием между векторами двух слов будет являться косинусное сходство, вычисляемое по следующей формуле [6, с. 104]:
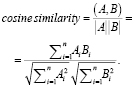
Одним из параметров модели будет размерность векторного представления, минимальная частота слов для отбора в словарь, а также размер скользящего окна. Минимальная частота слов для отбора в словарь будет равняться также десяти, а размер скользящего окна трем, а размерность векторов около двухсот. Результатом является способность модели на основе полученного слова, представленного в виде входного вектора, предсказать результат распределения вероятностей данного слова быть в контексте с другими на всем их множестве. Для иллюстрации вышесказанного осуществим нахождение близких по контексту слов через вычисление косинусного сходства (табл. 2).
Таблица 2
Вероятность появления в контекстном окружении слов
|
Входное слово |
Контекстное окружение |
Вероятность появления слов, % |
|
сотовый |
подвижный |
96 |
|
радиотелефонный |
90 |
|
|
мобильный |
84 |
|
|
интернет |
высокоскоростной |
70 |
|
широкополосный |
69 |
|
|
представление |
68 |
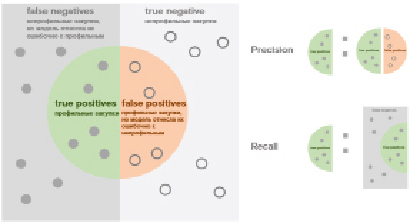
Рис. 3. Метрики для оценки модели машинного обучения
После совершения полной предобработки данных следует третий этап методологии KDD – Data Mining. Выбор методов машинного обучения объясняется их практической применимостью для решения задач классификации [7, с. 11-12]:
1. Логистическая регрессия (LR) – при применении данного метода происходит определение вероятности, с которой входное значение относится к определенному классу, в частности, в случае бинарной логистической регрессии осуществляется разделение исходного пространства границей на две части.
2. Градиентный бустинг (XGB) – при применении данного метода происходит построение предсказаний на основе слабых моделей, которые объединяются в ансамбль и на каждой итерации их последовательного применения предсказательная способность всей модели повышается.
3. Ближайшие соседи (KNN) – при применении данного метода входные значения классифицируются в зависимости от принадлежности к одному из классов его ближайших, соседних, значений на основе определения расстояния между входным значением и уже классифицированными значениями.
После разработки модели машинного обучения предстоит этап оценки моделей на основе метрик [8, с. 12] (рис. 3).
Получены результаты оценки модели машинного обучения на тестовой выборке, а также рассчитаны метрики (табл. 3).
Таблица 3
Оценка моделей машинного обучения на тестовой выборке, %
|
Способ кодирования |
Прямое кодирование |
Векторное представление |
||||
|
Метод машинного обучения |
LR |
XGB |
KNN |
LR |
XGB |
KNN |
|
Наименование метрики |
||||||
|
Precision |
97,2 |
96,6 |
97,5 |
94,6 |
95,9 |
96 |
|
Recall |
95,4 |
95,7 |
92,4 |
93,3 |
95,1 |
93,6 |
|
F-Measure |
96,3 |
96,2 |
94,9 |
94 |
95,5 |
94,8 |
Таблица 4
Расчет затрат на классификацию закупок с использованием модели машинного обучения
|
Операция ручной классификации закупок |
Частота выполнения, раз/мес. |
Трудоемкость, минут |
Денежные затраты, руб (ставка 1 000 руб./час) |
|
Отчет об участии в закупках по профилю «Мобильная связь» |
1 |
57 |
950 |
|
Отчет о выигранных закупках по профилю «Связь» |
4 |
20 |
1 333 |
|
Отчет о закупках по профилю «Связь» с отказами от участия |
1 |
60 |
1 000 |
|
Итого |
197 |
3 283 |
Таблица 5
Расчет экономии средств
|
Показатели |
Затраты |
Абсолютные показатели затрат, мес. |
Относительное изменение затрат, % |
Индекс изменения затрат |
|
|
До |
После |
||||
|
Трудоемкость |
T0, минут |
T1, минут |
ΔT = T0 – T1 |
|
|
|
4 700 |
197 |
4 503 |
96 |
24 |
|
|
Стоимость |
C0, руб./мес. |
C1, руб./мес. |
ΔС = С0 – С1 |
|
|
|
78 333 |
3 283 |
75 050 |
96 |
24 |
|
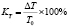
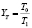
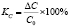
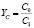
Необходимо отметить тот факт, что способ прямого кодирования показывает более высокие значения метрик как на обучающей, так и на тестовых выборках, чем способ векторного представления, что можно объяснить заданными правилами описания объекта закупки, регламентирующиеся Федеральными законами N 44-ФЗ и N 223-ФЗ. Другими словами, закупки, размещаемые на электронных площадках, именуются согласно общероссийскому классификатору продукции по видам экономической деятельности. В данном случае, модели машинного обучения на основе способа прямого кодирования демонстрируют лучшие результаты, так как содержащийся в его структуре мешок слов располагает возможностью кодирования структуры классификатора, насколько это возможно исходя из объема выборки и состава уникального словаря. Так как процесс обучения модели машинного обучения характеризуется итеративностью, в частности, в плане работы с исходным текстовым корпусом, для дальнейшего возможного улучшения показателей метрик появляется задача в дополнении исходного текстового корпуса новыми наименованиями непрофильных закупок в целях увеличения словарного запаса.
Выводы
В ходе разработки моделей машинного обучения и их применения на основе новых, ранее не известных для моделей, данных в рамках подготовки аналитических отчетов достигнуты следующие результаты:
1. Сокращение временных затрат на проведение классификации до 96 %, что составляет индекс их изменения в 24 раза;
2. Повышение исполнительской дисциплины – полное исключение фактов нарушения контрольных сроков в ходе подготовки аналитического отчета;
3. Сокращение стоимости операций до 96 %, что составляет индекс их изменения в 24 раза.
Произведен расчет затрат на классификацию закупок с использованием модели машинного обучения и расчет экономии средств (табл. 4-5).
Библиографическая ссылка
Желябин Д.В. ПРИМЕНЕНИЕ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РЕШЕНИЯ ЗАДАЧИ NLP КЛАССИФИКАЦИИ ТЕКСТА НА ОСНОВЕ АНАЛИЗА СЕМАНТИКИ ЕСТЕСТВЕННОГО ЯЗЫКА // Вестник Алтайской академии экономики и права. – 2020. – № 6-2. – С. 229-235;URL: https://vaael.ru/ru/article/view?id=1187 (дата обращения: 19.04.2024).